How do I configure an S3 log source in Panther with a prefix exclusion or inclusion?
QUESTION
When using AWS S3 as a data transport to add a log source to Panther, how do I use a prefix for exclusion or inclusion?
ANSWER
To include only files in a specific folder within your S3 bucket, you can use a prefix filter. You can add as many prefix filters as you need.
If you need to specify a folder not to pull logs from, you can use an exclusion filter.
Where to configure Prefix Filters in Panther
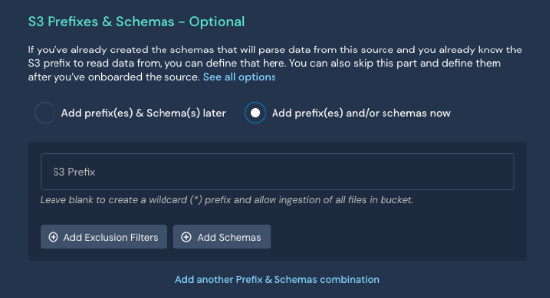
While creating a new log source
You can add prefix filters while configuring a new log source. See the Panther documentation for instructions on configuring a new S3 log source.
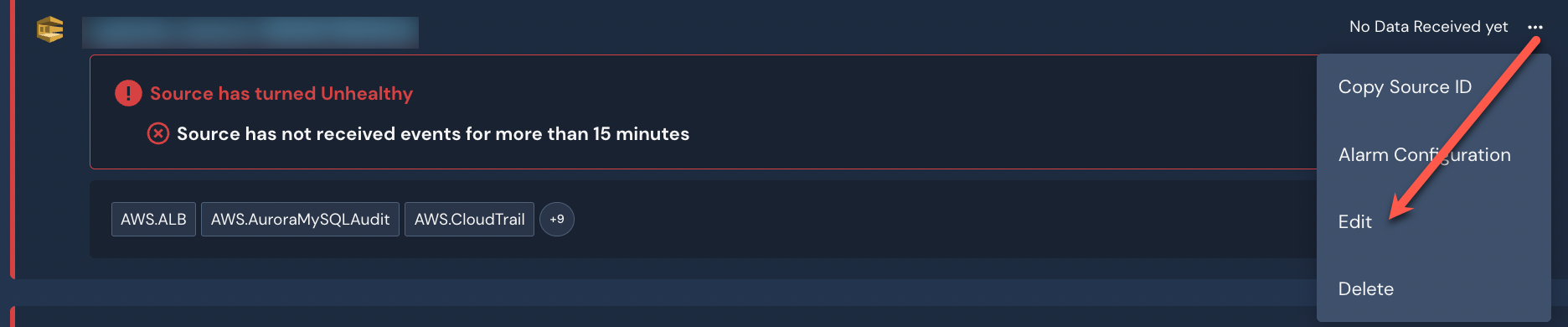
While editing an existing log source
To edit a log source:
- In the Panther Console, navigate to Configure > Log Sources.
- In the list of sources, locate the log source you want edit.
- In the right side of the source tile, click ..., then click Edit in the dropdown menu.
- Scroll down to the "S3 Prefixes & Schemas - Optional" section.
- After adding prefixes, scroll to the top of the page and click Save in the upper right corner.
How to write a Prefix Filter
An S3 object key has the following form:
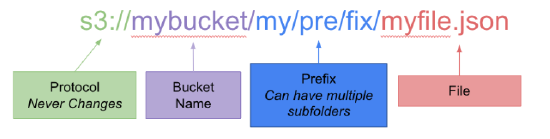
s3://mybucket/my/pre/fix/myfile.json
The bucket name defines the root of the file system. The prefix includes anything between the bucket name and the end of the file path (AKA S3 Object Key). Using the key above, any of the following would be valid prefixes:
my/pre/fix/my/pre/my/mp/pre/fix/myfile
Note that you aren't limited to just paths as prefixes; the last example shows you can also include parts of filenames as a prefix.
Using wildcards
Starting in Panther v.1.41, you can use wildcards in the Exclusion Filters of your Prefix. Wildcards are denoted by the asterisk symbol (*).
For example, suppose you want to include logs from 2 locations:
- mylogs/FIRST_AWS_ACCOUNT/CloudTrail
- mylogs/SECOND_AWS_ACCOUNT/CloudTrail
You can include both directories with a single prefix: mylogs/*/CloudTrail.
Note: Wildcards can include multiple subfolders; the prefix root/*/baz would match root/foo/baz and root/foo/bar/baz.
Note: Wildcards are not supported in the Prefix itself; they can only be used in the Exclusion Filter.
What do Exclusion Filters do?
By default, a prefix filter is an Inclusion Filter - it only lets Panther ingest files that are nested within the prefix. On the other hand, an Exclusion Filter does the opposite; Panther will ingest all files in the bucket, except any files nested beneath the Exclusion Prefix.
For example, suppose you have an S3 bucket with all your logs, and you make a folder called MySensitiveLogs in the root of your S3 bucket. In this folder is sensitive log info that you'd prefer Panther not ingest. When setting up this bucket as a Log Source in Panther, you can add MySensitiveLogs/ as an Exclusion Filter, and Panther will ingest all the other files in the bucker, while ignoring the sensitive ones.