Why are all my incoming logs only matching 1 schema?
Issue
I have multiple custom schemas for a log source, but all my incoming logs keep matching the same one.
Example: I have a log source which contains logs for two apps: an nginx server and a web app called Webby. Both apps output logs with different formats, so I defined two schemas for this log source; one for each app. However, all the logs being imported into Panther are being parsed as nginx logs, even the web app ones.
Resolution
The issue can be solved in a few ways:
If using S3 to onboard your logs...
Consider using prefix filtering. Have each data source send its logs to a prefixed location within your S3 bucket. Then, when creating the log source in the Panther Console (or editing a previously created source), specify the prefixes for each log type. You can direct logs with specific prefixes to use individual schemas. This is the safest method and is recommended wherever possible.
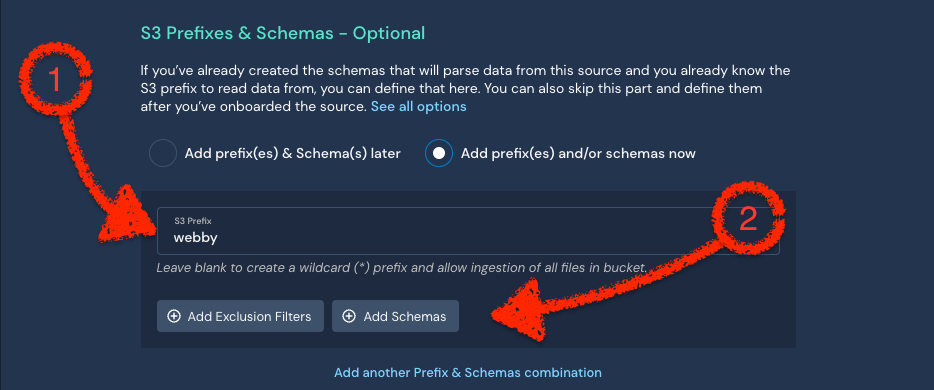
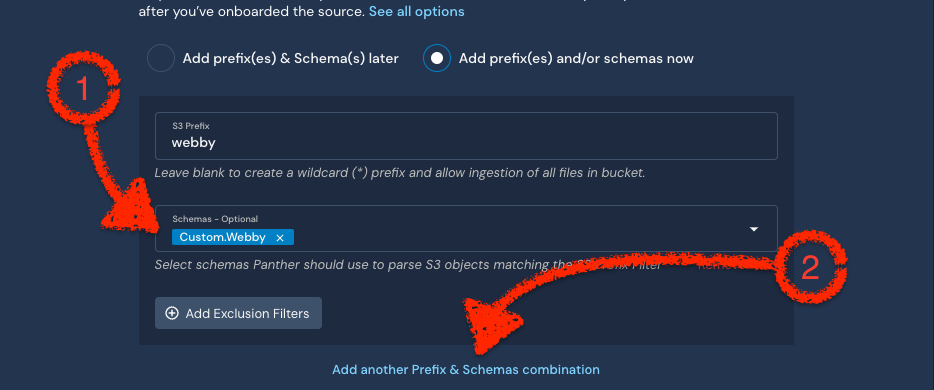
Example: Suppose you've configured both logs to be saved in the root directory of your S3 bucket. Instead, configure the logs to be saved to separate folders, such as /nginx and /webby Then, in the Panther console, edit or create the log source. Under the S3 Prefixes & Schemas, specify the folder names (these are the prefixes we're talking about).
|
 |
|
 |
If not using S3...
If you can't use prefix filtering as mentioned above, then you need to make the log schemas mutually exclusive. Consider which fields both schemas have in common, and which are specific to one or the other. In each schema, look for a field which is required, and not used in any other schema. Set this field to required (as detailed here). One exclusive required field per schema will guarantee that any correctly formatted logs will match only one schema.
Example: Suppose all nginx logs have a field called "level", which is never used in any Webby logs. Likewise, suppose Webby logs have a field called "webby_token_id", which never appears in nginx logs. By defining both fields as required in their respective schemas, you can prevent any false matches for incoming logs.
# nginx schema
version: 0
fields:
- name: date
type: timestamp
- name: level
type: integer
required: true
- name: message
type: string
...
|
# webby schema
version: 0
fields:
- name: date
type: timestamp
- name: webby_token_id
type: string
required: true
- name: actor
type: object
....
|
Alternatively, if each schema shares a single field, but each allows different values, utilize the allow feature of the schema definitions. For example, if Schema A and Schema B both have a field named "app_name", but one is always equal to "nginx" and the other always equals "apache", then you can specify this in the schema definition and allow this to determine which schema to use for the rest of the fields.
Example: What if Webby also includes a field called "level"? Suppose it does, but in Webby's logs, the "level" field is a string enum with values "INFO", "DEBUG", "WARN", etc, while the "level" field in nginx used integers. We can configure the schema to sort applicability based on the value of the "level" field.
# nginx schema
...
- name: level
type: integer
required: true
validate:
deny: ["DEBUG", "INFO", "WARN", "ERROR"]
...
|
# webby schema
...
- name: level
type: string
required: false
validate:
allow: ["DEBUG", "INFO", "WARN", "ERROR"]
...
|
A note on exclusivity: do your best to ensure schemas are mutually exclusive. Any arbitrary log should only be able to match one schema. If Log A matches Schema A, but Log B matches Schema A and Schema B, you risk the chance that the log is parsed using the wrong schema. Currently, Panther matches logs against each listed schema in alphabetical order, and it accepts the first schema which doesn't raise any errors. It does not scan through all schemas and choose the best match. For that reason, it's best to ensure that logs of type B will only match Schema B, and not any other schemas.
Cause
Most often, this is due to schemas with too broad criteria. If one schema, or multiple, can match logs with multiple formats, then logs can be parsed incorrectly.